
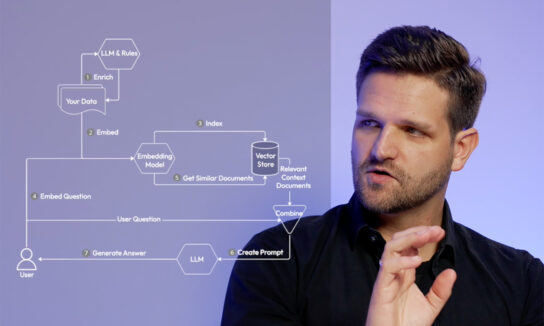
In our video “Generative AI on your own data”, we saw how RAG (Retrieval Augmented Generation) is a great way to customize a generative AI model. In summary, any system that introduces a retrieval step to add contextual information to the prompt can be considered a form of RAG (Figure 1).
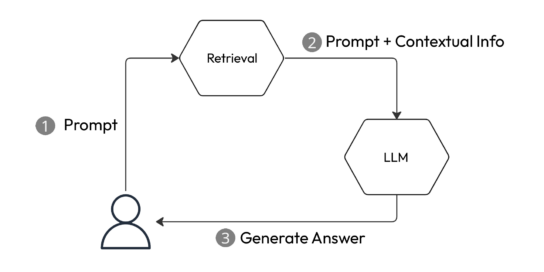
Figure 1: A basic RAG system
In this blog post, we want to go beyond that and explore what else RAG can do. We will look into the Agentic RAG systems that have created a lot of buzz lately and also explore why some people praise RAG as a solution to LLM hallucinations while others question the entire paradigm exactly because of those hallucinations.
Agentic RAG
The current excitement around RAG focuses on creating sophisticated agent systems, known as Agentic RAG. These systems go beyond the basic framework shown in Figure 1. Instead of merely retrieving context and generating responses, these advanced systems empower the LLM to decide which agents or tools to use for completing a given task. This can include searching the web, utilizing a calculator, or interfacing with various APIs, all based on the input it receives.
The excitement stems from two main factors: (1) popular RAG frameworks like LlamaIndex and Langchain have incorporated support for this use case, actively promoting and pushing the paradigm to their users, and (2) the paradigm is effective, enabling the creation of truly impressive applications.
The core of this innovation lies in the LLMs themselves. Models such as GPT, Llama, and Claude can decompose tasks into multiple steps and have added functionality for utilizing external tools. As a developer, you can include a list of tool specifications in your prompts. These tool specs may have to be described differently for each LLM, but the idea is always the same: You provide a name, a description of what the tool does, and a schema for its input. What parameters are required? What optional parameters are supported? Which type does each parameter have? Figure 2 shows an example of such a tool for Anthropic’s Claude model, but other models offer similar capabilities. The LLMs then have been trained to work with that. For a user query, they can decide whether it is worthwhile to use one or more of the available tools, and they can produce the proper call for the tool.
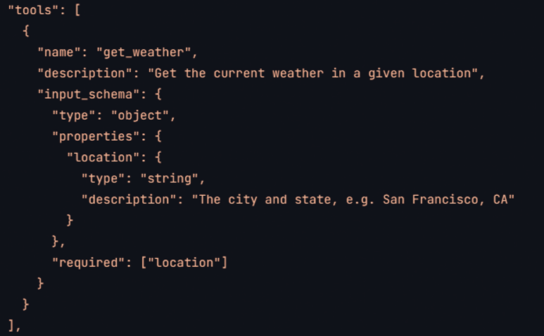
Figure 2: Example tool specification for Anthropic’s Claude model (source: https://docs.anthropic.com/en/docs/tool-use)
Clearly, this is an incredibly powerful instrument. You can target all kinds of APIs (public and internal to your organization) and turn simple and complex RAG applications into specialized agents themselves.
Let’s look at two examples: (1) a simple orchestration of individual RAG applications and (2) a system in which agents not only retrieve information but also perform actions on behalf of the AI.
For the first example, think of an election with many parties, like the elections to the EU parliament, and an application that allows you to compare the parties’ standpoints on various topics. For example, you might ask, “What is the difference between the stance of party A, party C, and party F towards AI regulation?” A great way to enable this is to process each party’s manifesto and to build an agent that answers questions about that party’s stance towards a topic. Then you combine all these agents, and the final system can analyze the question, choose the right agents for the particular question, retrieve their results, and then create a contextualized prompt with the individual results to perform the comparison.
In contrast, suppose you have just built a single RAG application and indexed all the manifestos in one vector store. In that case, the retrieval step might have difficulty ensuring that documents about each of the required parties would be retrieved and that relevant snippets wouldn’t be dominated by content from only a few manifestos.
But Agentic RAG doesn’t stop there. Crucially, agent tools can perform actions and exceed “read-only” territory. They are not limited to retrieval and generating chat output. Think of an agent using a calendar tool. If your calendar offers an API, and you supply a good description of that API to the agent, your LLM can interact with your calendar – in both ways! Now, let’s say you’re using this agent together with a retrieval agent based on your organization’s internal knowledge platform.
Suddenly, the following series of commands is entirely plausible:
> What meetings do I have tomorrow?
...
> The 10:00 meeting is interesting. What information does our knowledge platform have on that topic? Please summarize.
...
> Who are the main contributors to these topics?
...
> Add them to the meeting, please.
Obviously, the productivity gains from such a system can be substantial. In practice, however, most people may want to stop before the last command and avoid the call to action. This is because these systems have not (yet?) built the necessary trust. There is too much that can go wrong. Without manually ensuring the AI did not hallucinate, users hesitate before initiating actions.
The Usefulness – Reliability Dilemma
The above example is just one of many ways in which trust in AI-generated answers is still far from perfect. Everyone has seen an LLM hallucinate, sometimes harmless, sometimes annoying, and sometimes outright funny due to its absurdity.
Interestingly, RAG is sometimes described as the solution to that issue. The idea is simple: If your answer is not based on some knowledge hidden in information internalized within the model’s weights but on the clear context provided as part of the prompt, this context can serve as references and evidence for how the model arrived at that conclusion.
While this is true in principle, it only works if the application is simple enough. If you built a chatbot based on RAG that is little more than a way to search in a text corpus semantically, your chatbot can produce answers and clear references to the relevant part. However, these systems must accept a different kind of criticism: Are they even useful or just a shiny but slow interface to search?
Only when it is necessary to reason over several different bits of information, RAG applications clearly exceed the capabilities of traditional search systems. The above example with the party manifestos goes in that direction. However, references that build trust in the app’s responses are also much harder to produce: Did we retrieve the most relevant information for each party, or is the information retrieved at least representative? Did the model then draw the right conclusion for the comparison? Double-checking the AI on all these things is far too tedious or impossible for users.
Conclusion
It is easy to argue that RAG applications are incredibly powerful tools that can yield huge productivity gains. It is also easy to argue that RAG applications can actually mitigate the issues with hallucination and build trust. However, as discussed in this post, the two arguments can rarely be made for the same application. Certainly, they do not apply to every possible RAG application. So many things qualify as RAG, and the complexities can be trivial to nearly unlimited.
In practice, this means finding the right level of complexity. The application has to be powerful enough to justify using a computationally expensive AI model, but it must also not be so complex that it becomes unreliable.
In a world where frameworks like LlamaIndex and API access to LLMs allow anyone to build basic RAG apps, there has to be some challenge left for us to solve. Let’s address it together. Contact CID.




