
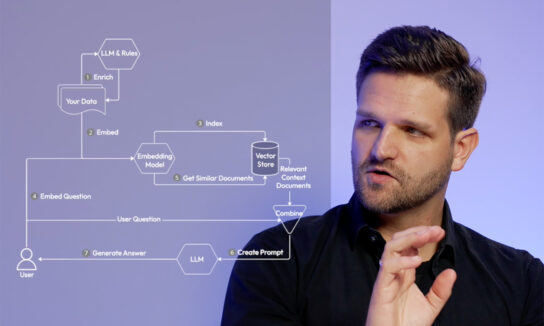
In unserem Video „Generative AI on your own data“ haben wir gesehen, dass RAG (Retrieval Augmented Generation) eine großartige Möglichkeit ist, ein generatives KI-Modell auf die eigenen Bedürfnisse anzupassen. Prinzipiell kann jedes System, das einen Retrieval-Schritt mit zusätzlichen kontextuellen Informationen zur Eingabe nutzt, als eine Form von RAG betrachtet werden (Abbildung 1).
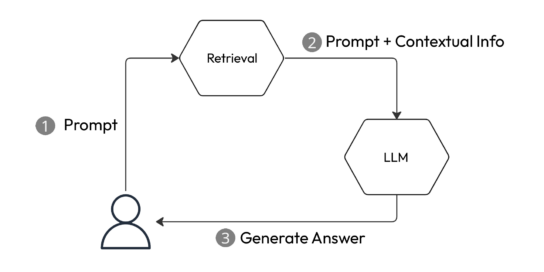
Abbildung 1: Ein einfaches RAG-System
In diesem Blogbeitrag möchten wir hierüber hinausgehen und uns damit beschäftigen, was RAG noch leisten kann. Wir werden uns Agentic RAG-Systeme ansehen, die in letzter Zeit viel Aufmerksamkeit erregt haben, und auch untersuchen, warum einige Leute RAG als Lösung für LLM-Halluzinationen loben, während andere das gesamte Paradigma genau wegen dieser Halluzinationen infrage stellen.
Agentic RAG
Im Zusammenhang mit RAG erfahren aktuell ausgefeilte Agentensysteme, die als Agentic RAG bekannt sind, viel Aufmerksamkeit. Diese Systeme gehen über das einfache Framework, das in Abbildung 1 gezeigt wird, hinaus. Statt lediglich Kontext abzurufen und Antworten zu generieren, ermöglichen diese Systeme es dem LLM, zu entscheiden, welche Agenten oder Werkzeuge für die Erledigung einer bestimmten Aufgabe verwendet werden sollen. Dies kann eine Internetsuche, die Nutzung eines Taschenrechners oder Schnittstellen zu verschiedenen APIs umfassen, alles basierend auf den erhaltenen Eingaben.
Das große Interesse für diese Art Systeme hat zwei Hauptgründe: (1) Beliebte RAG-Frameworks wie LlamaIndex und Langchain haben Unterstützung für diesen Anwendungsfall integriert und fördern das Paradigma aktiv bei ihren Nutzern, und (2) das Paradigma ist effektiv und ermöglicht die Schaffung wirklich beeindruckender Anwendungen.
Im Zentrum dieser Innovation stehen die LLMs selbst. Modelle wie GPT, Llama und Claude können Aufgaben in mehrere Schritte zerlegen und haben zusätzliche Funktionen zur Nutzung externer Werkzeuge. Entwickler können eine Liste von Werkzeug-Spezifikationen in ihre Prompts einfügen. Diese Werkzeugspezifikationen können für jedes LLM im Detail etwas unterschiedlich aussehen, aber die Idee ist immer dieselbe: Man gibt einen Werkzeugnamen an, sowie eine Beschreibung dessen, was das Werkzeug tut, und ein Schema für seine Eingabe. Welche Parameter sind erforderlich? Welche optionalen Parameter werden unterstützt? Welchen Typ hat jeder Parameter? Abbildung 2 zeigt ein Beispiel für eine solche Werkzeugspezifikation für das Claude-Modell von Anthropic, aber andere Modelle bieten ähnliche Möglichkeiten. Die LLMs wurden darauf trainiert, hiermit zu arbeiten. Bei einer Benutzeranfrage können sie entscheiden, ob es sinnvoll ist, eines oder mehrere der verfügbaren Werkzeuge zu verwenden, und sie können den richtigen Aufruf für jedes Werkzeug erstellen.
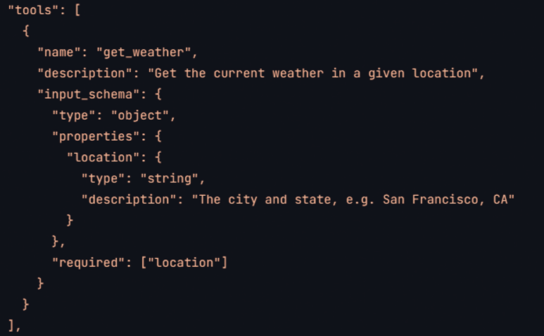
Abbildung 2: Beispiel einer Werkzeugspezifikation für das Claude-Modell von Anthropic (Quelle: https://docs.anthropic.com/en/docs/tool-use)
Wir haben es hier ganz klar mit einem extrem leistungsfähigen Instrument zu tun. Es erlaubt uns, alle Arten von APIs (öffentliche wie organisationsinterne) anzusprechen und so einfache und komplexe RAG-Anwendungen in spezialisierte Agenten zu verwandeln.
Schauen wir uns zwei Beispiele an: (1) eine einfache Orchestrierung einzelner RAG-Anwendungen und (2) ein System, in dem Agenten nicht nur Informationen abrufen, sondern auch für die KI Aktionen ausführen.
Für das erste Beispiel stellen wir uns eine Wahl mit vielen Parteien, wie die Wahlen zum EU-Parlament vor, und eine Anwendung, die es uns ermöglicht, die Standpunkte der Parteien zu verschiedenen Themen zu vergleichen. Wir könnten zum Beispiel fragen: „Was ist der Unterschied zwischen der Haltung von Partei A, Partei C und Partei F zur Regulierung von KI?“ Ein sehr guter Ansatz wäre es hier, die Wahlprogramme jeder Partei zu verarbeiten und je einen Agenten zu erstellen, der Fragen zur Haltung dieser Partei zu einem Thema beantwortet. Im Anschluss können wir all diese Agenten kombinieren. Das resultierende System kann unsere Frage analysieren, die richtigen Agenten für die jeweilige Frage auswählen, deren Ergebnisse abrufen und dann einen kontextualisierten Prompt mit den einzelnen Ergebnissen erstellen, um den Vergleich durchzuführen.
Im Gegensatz hierzu stellen wir uns nun einmal kurz vor, wir hätten eine einzige RAG Anwendung entwickelt und alle Wahlprogramme in einem großen Vektorspeicher indiziert. Unser Retrieval-Schritt könnte nun Schwierigkeiten haben sicherzustellen, dass Dokumente über jede der erforderlichen Parteien abgerufen werden und dass relevante Ausschnitte nicht von Inhalten nur weniger Wahlprogramme dominiert werden.
Und es gibt noch einen weiteren, wichtigen Vorteil von Agentic RAG Systemen. Ein entscheidendes Merkmal ist, dass Agentenwerkzeuge Aktionen ausführen können, die über das reine „Lesen“ von Informationen hinausgehen. Sie sind also nicht auf das Abrufen und Generieren von Chat-Ausgaben beschränkt. Stellen wir uns beispielsweise einen Agenten vor, der ein Kalenderwerkzeug verwendet. Wenn der hier verwendete Kalender eine API anbietet und dem entsprechenden Agenten eine korrekte Beschreibung dieser API zur Verfügung steht, dann kann unser LLM mit unserem Kalender interagieren – in beide Richtungen! Angenommen, wir verwenden diesen Agenten nun zusammen mit einem Retrieval-Agenten, der auf eine interne Wissensplattform unserer Organisation zugreift.
Plötzlich ist die folgende Abfolge von Befehlen vorstellbar:
> Welche Meetings habe ich morgen?
...
> Das Meeting um 10:00 Uhr ist interessant. Welche Informationen hat unsere Wissensplattform zu diesem Thema? Bitte zusammenfassen.
...
> Wer sind die Hauptbeitragenden zu diesen Themen?
...
> Bitte füge sie zu dem Meeting hinzu.
Es ist offensichtlich, dass die Produktivitätsgewinne durch ein solches System erheblich sein können. In der Praxis möchten jedoch die meisten Menschen möglicherweise vor dem letzten Befehl aufhören und die Handlungsaufforderung lieber nicht geben. Dies liegt daran, dass Nutzer (noch?) nicht das notwendige Vertrauen in diese Systeme aufgebaut haben. Es gibt zu viele mögliche Fehlerquellen. Ohne manuell sicherzustellen, dass die KI nicht halluziniert hat, zögern die Benutzer, bevor sie Aktionen auslösen.
Das Nützlichkeits-Zuverlässigkeits-Dilemma
Das obige Beispiel ist nur eine von vielen Situationen, in denen das Vertrauen in KI-generierte Antworten noch nicht hinreichend groß ist. Jeder hat schon einmal gesehen, wie ein LLM halluziniert, manchmal harmlos, manchmal ärgerlich und manchmal einfach absurd komisch.
Interessanterweise wird RAG manchmal als Lösung für dieses Problem beschrieben. Die Idee ist einfach: Wenn die Systemantwort nicht auf internem Wissen beruht, das versteckt in Modellgewichten gespeichert ist, sondern auf einem klaren Kontext, der Teil des Prompts ist, dann kann dieser Kontext auch als Referenz und Nachweis dafür dienen, wie das Modell zu seinem Schluss gekommen ist.
Dies stimmt zwar im Prinzip, funktioniert aber nur, wenn die Anwendung einfach genug ist. Haben wir einen Chatbot auf RAG-Basis erstellt, der wenig mehr ist als eine Möglichkeit, in einem Textkorpus semantisch zu suchen, dann kann dieser Chatbot auch Antworten und klare Verweise auf den relevanten Teil liefern. Doch solche Systeme müssen sich eine andere Art von Kritik gefallen lassen: Sind sie überhaupt nützlich oder nur eine hochpolierte, aber langsame Schnittstelle zur Suche?
Nur wenn es nötig ist, Schlussfolgerungen auf der Basis von unterschiedlichsten Informationen zu ziehen, übertreffen RAG-Anwendungen eindeutig die Fähigkeiten traditioneller Suchsysteme. Das obige Beispiel mit den Wahlprogrammen geht in diese Richtung. Allerdings sind Nachweise, die das Vertrauen in die Antworten der App erhöhen würden, auch schwierig zu erstellen: Haben wir die relevantesten Informationen für jede Partei abgerufen, oder sind die abgerufenen Informationen zumindest repräsentativ? Hat das Modell dann die richtige Schlussfolgerung für den Vergleich gezogen? Die KI in all diesen Dingen nachzuprüfen, ist für Benutzer viel zu mühsam oder unmöglich.
Fazit
Es lässt sich leicht argumentieren, dass RAG-Anwendungen unglaublich leistungsstarke Werkzeuge sind, die die Produktivität enorm steigern können. Es lässt sich auch leicht argumentieren, dass RAG-Anwendungen tatsächlich Probleme mit Halluzinationen mindern und Vertrauen aufbauen können. Wie in diesem Beitrag diskutiert wurde, können jedoch selten beide Argumente für dieselbe Anwendung vorgebracht werden. Sicherlich gelten sie nicht für jede mögliche RAG-Anwendung. So viele Dinge fallen in den großen Bereich RAG, und die Komplexitäten können trivial bis nahezu unbegrenzt sein.
In der Praxis bedeutet das, dass es wichtig ist, das richtige Maß an Komplexität zu finden. Die Anwendung muss leistungsfähig genug sein, um die Verwendung eines rechnerisch teuren KI-Modells zu rechtfertigen, darf aber auch nicht so komplex sein, dass sie unzuverlässig wird.
In einer Welt, in der Frameworks wie LlamaIndex und der API-Zugriff auf LLMs es an sich jedem ermöglichen, einfache RAG-Apps zu erstellen, bleiben somit für uns immer noch genügend Herausforderungen zu lösen. Gehen wir es gemeinsam an. Jetzt CID kontaktieren.
Weiterführende Inhalte

RAG – Schlüssel zu einer verbesserten, kontextgesteuerten, generativen KI-Nutzung

Entdecken Sie die vielfältigen Anwendungen generativer KI – von KI-Assistenten bis zu spezialisierten Tools, die Branchen verändern.

Erfahren Sie, wie Maschinelles Lernen Branchen revolutioniert, Aufgaben automatisiert und Entscheidungsprozesse verbessert. Wichtige Konzepte und praktische Anwendungen.




